目录:
- 云原生的发展历程
- 告别厂商绑定:云原生让多云混合云成为常态
- 云原生:AI、大数据的下一代基础设施
- 边缘计算:云原生技术,加速构建通用开放的云边协同平台




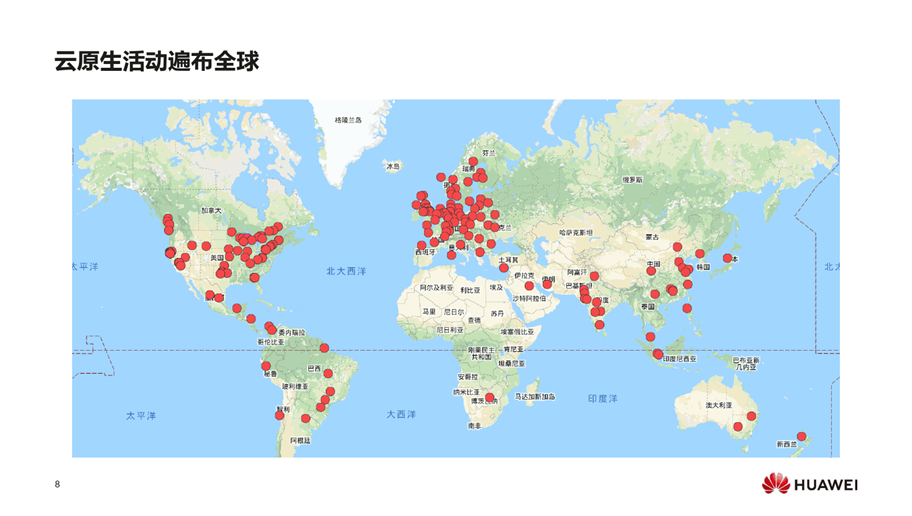
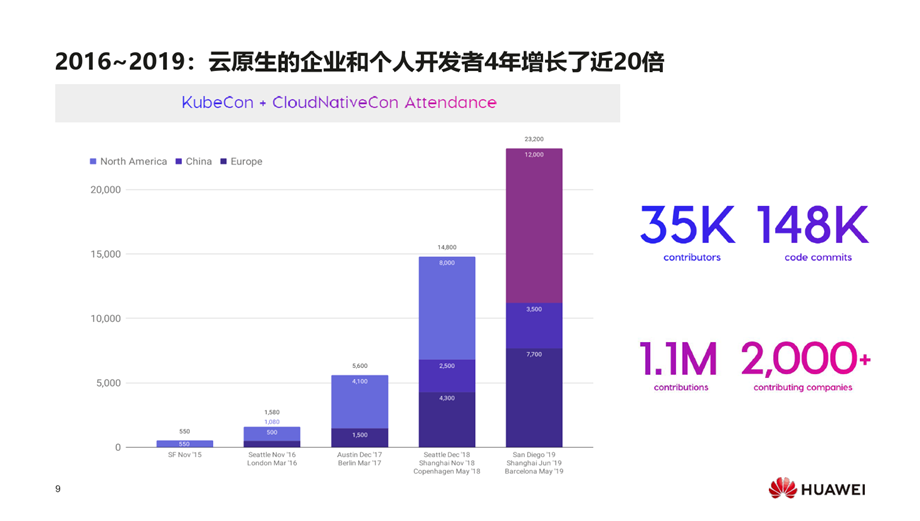
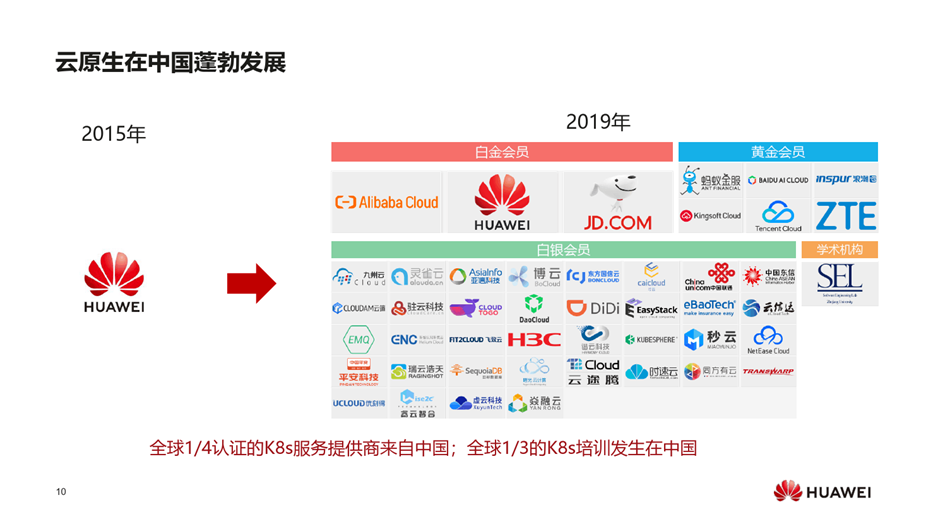
中国K8S服务提供商已超过50家,是全球整个生态的第三大贡献者。


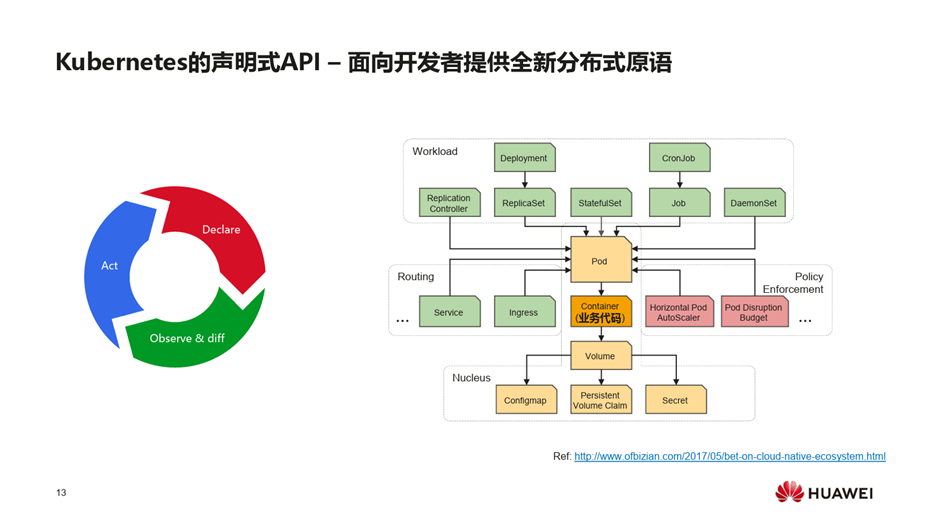
声明式API更像是面向对象的开发,命令式API更像是过程式开发,如果网络比较拥塞或变更比较频繁,整个系统处于比较大的响应压力下,声明式API比较容易做状态的合并,系统不用频繁做无效的变更。API对象的设计上是用彼此可以互补、组合的方式,比如用户要部署应用,要用到Deployment API、Replicaset API、Pod API、Service API,每类API都有对应的controller来处理它们的生命周期,通过对象间状态的联动来完成整个的生命周期,也可以引入自定义的API对象,通过对象间的不同组合来构建出复杂应用API的生命周期管理。
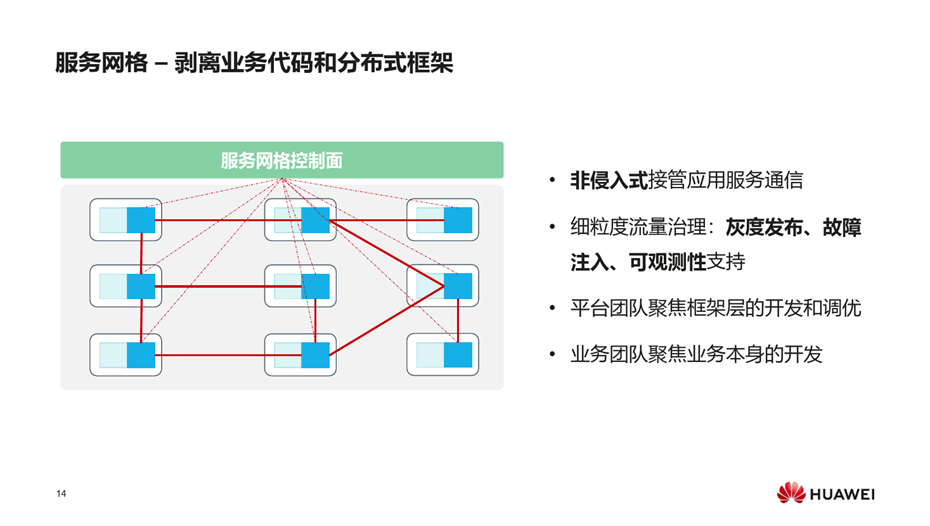
另一个代表技术是服务网格,服务网格是继Kubernetes之后的最火热的云原生技术之一,具有以下核心优势。
- 非侵入式接管应用服务通信;
- 细粒度流量治理:灰度发布、故障注入、可观测性支持;
- 平台团队聚焦框架层的开发和调优;
- 业务团队聚焦业务本身的开发。

2020年云原生在企业落地的3大趋势
- 多云&混合云
- 智能计算,大数据、AI、机器学习会大规模向云原生迁移
- 边缘计算

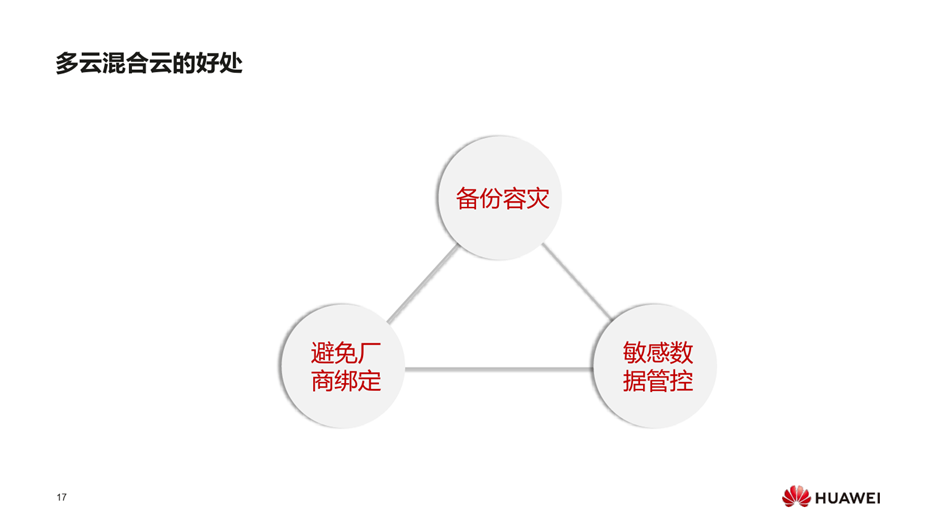
多云混合云的好处:
- 备份容灾
- 避免厂商绑定 ,充分利用各家云平台的业务能力
- 敏感数据管控 将核心数据控制私有云上,将高弹性、波动性大的业务部署在公有云上

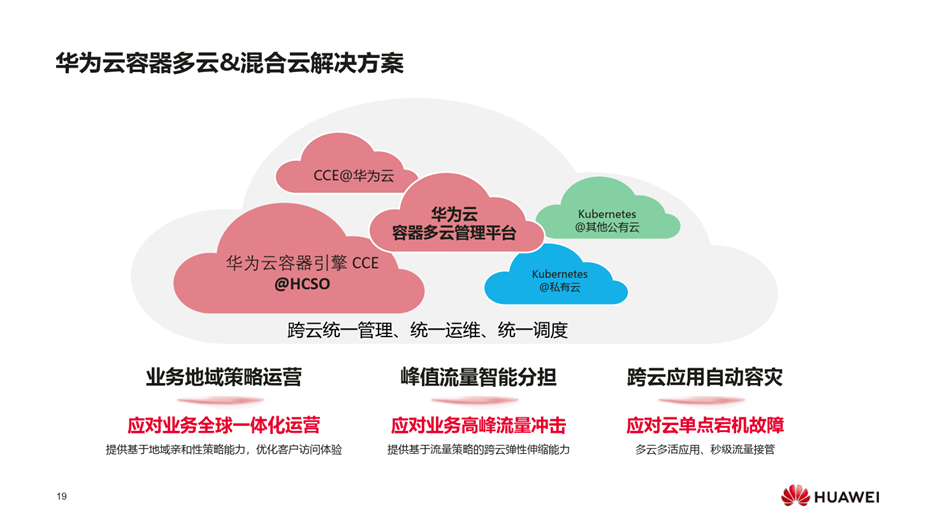



- 云原生的生态已构建了高度灵活、自动化、标准化的基础设施,资源的颗粒度很少,可以实现端到端的秒级的大规模弹性扩容,对AI、大数据瞬时并发压力比较大的业务比较契合
- 云原生对异构异建支持比较好,客户容易实现自己的加速器,满足对多元算力的需求,
- 借助kubernetes的多维度、多模型、易扩展的调度能力,比较容易实现集群利用率优化。

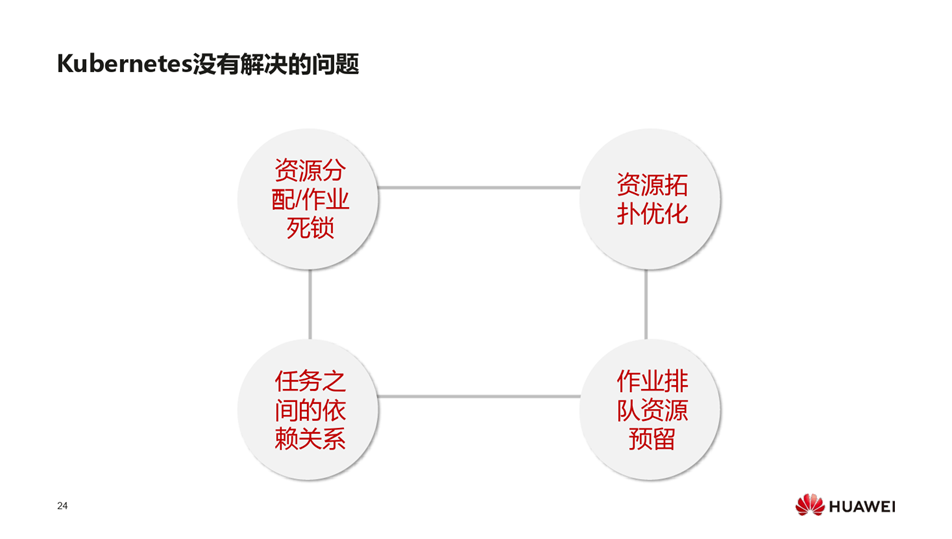
当有多个作业同时下发时,避免互相的等待,kubernetes不能很好考虑全局的资源分配的合理性问题,造成资源的死锁或某些任务的部分作业实例被启动,造成无效的CPU资源的分配;
AI场景中,以tensorflow为例,work节点有频繁网络交互的压力,如果按照每次只调度一个pod的模型,很可能将一个tensorflow集群的ps和work调度在集群中网络位置相对较远的位置,导致集群中网络交互压力大,可以通过模型,就近分布在一个机架上,通信的压力就会集中在机架的网络中,不会影响整个集群,乃至整个网络中心的带宽。
在基因测序的复杂作业中,作业之间有复杂的依赖关系,这是目前生态中比较缺乏的。
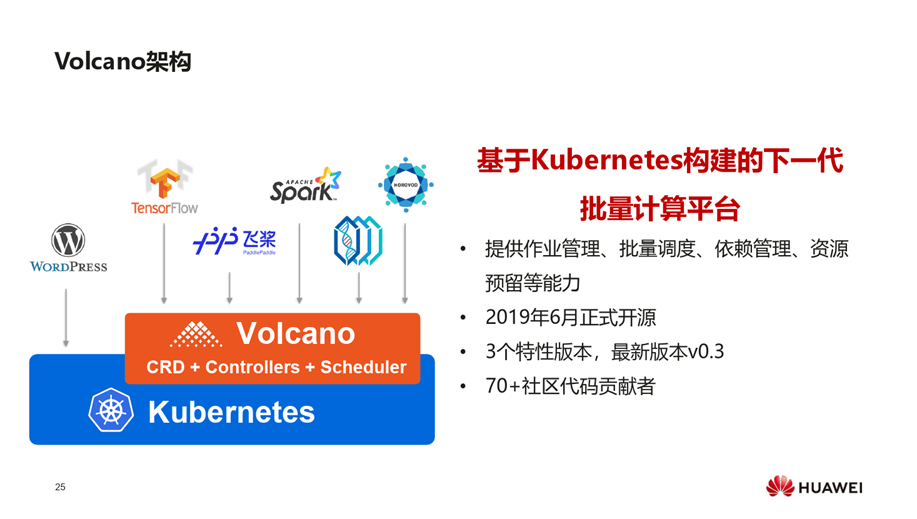
基于此,设计了Volcano的开源项目,面向批量计算的AI、大数据、基因测序等场景,提供作业管理、批量调度、依赖管理、资源预留等能力。将这类业务迁移到云原生上,统一底层的技术栈、资源池,可以更容易做全天候、全时段的资源分配。



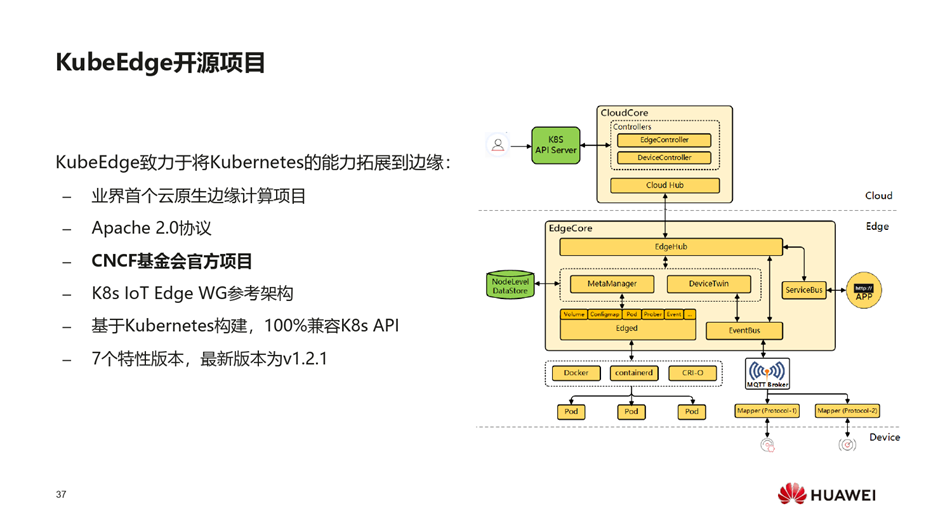
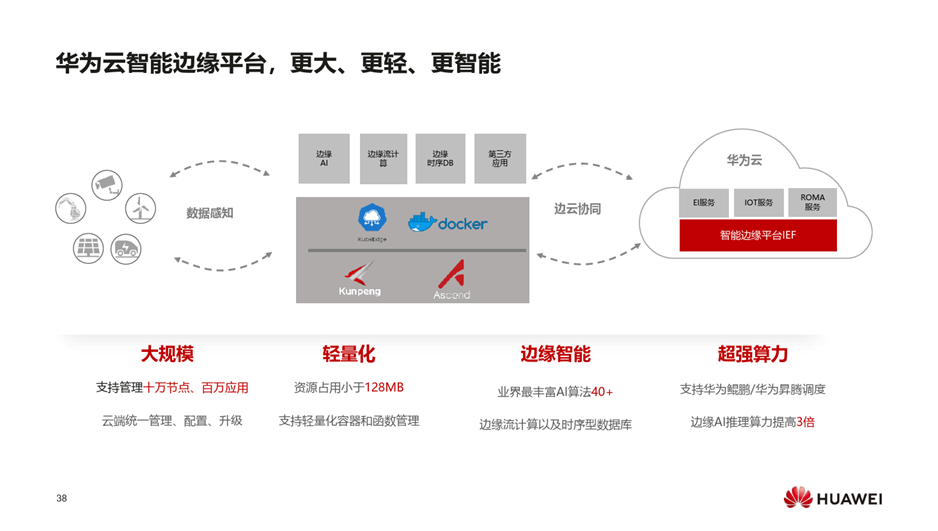
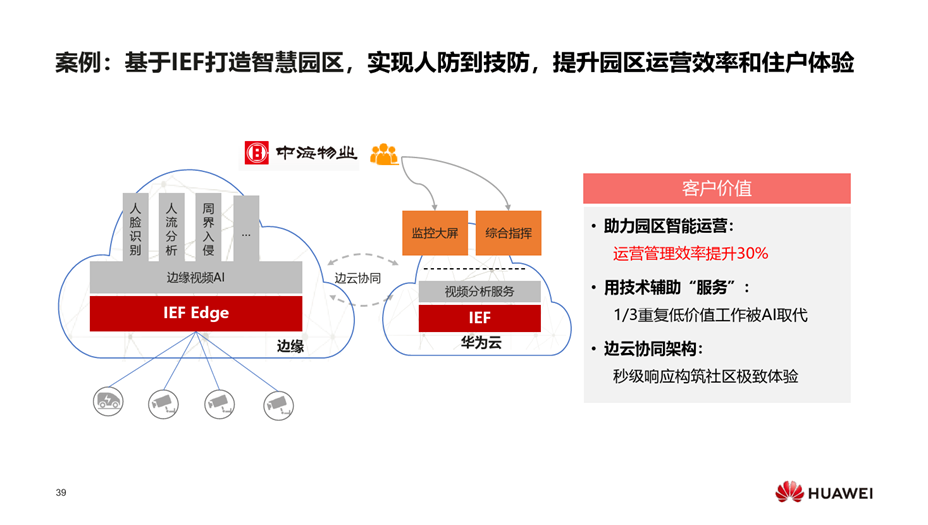
LT、工业互联网的共性的问题是互操作性,云原生可以很好地解决这个问题,
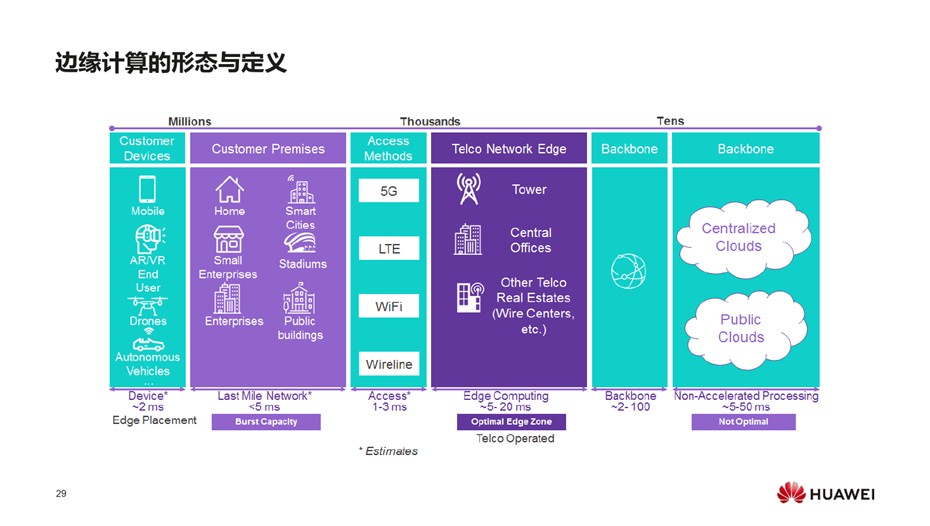
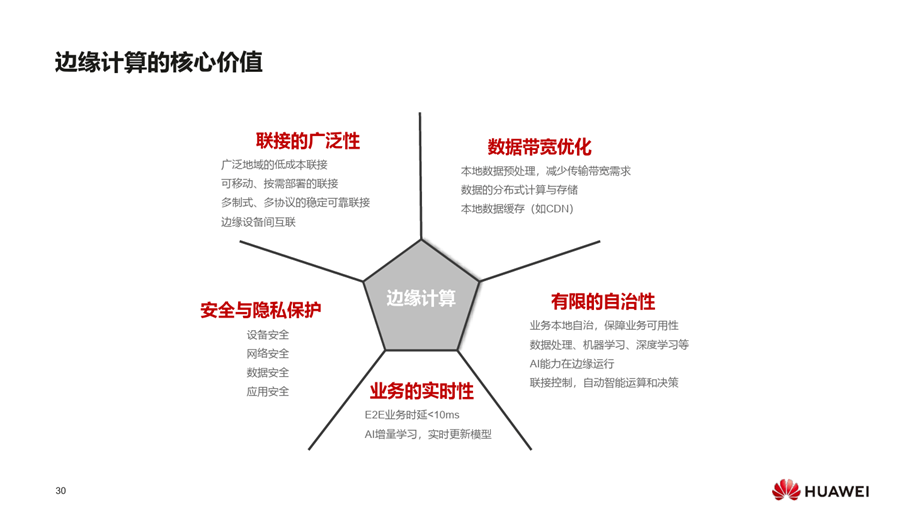

LT、工业互联网的平台有各自的协议和规范,对业务开发者来说,面临多重适配问题,云原生是互操作性的典范。

容器的镜像与传统的软件包最大的不同是容器的镜像不仅不含应用的交付件,还包括应用所依赖的环境,真正实现一次构建、到处运行。同时容器的镜像是分层的,开发者非常容易通过基础镜像的优化等手段做轻量化的改造,同时公共的基础镜像不会被重复的下载,是对应用的分发的非常好的优化。对平台的构建者来说,云原生的基础架构是松耦合、易扩展,开发者很容易构建自己的API和组件。

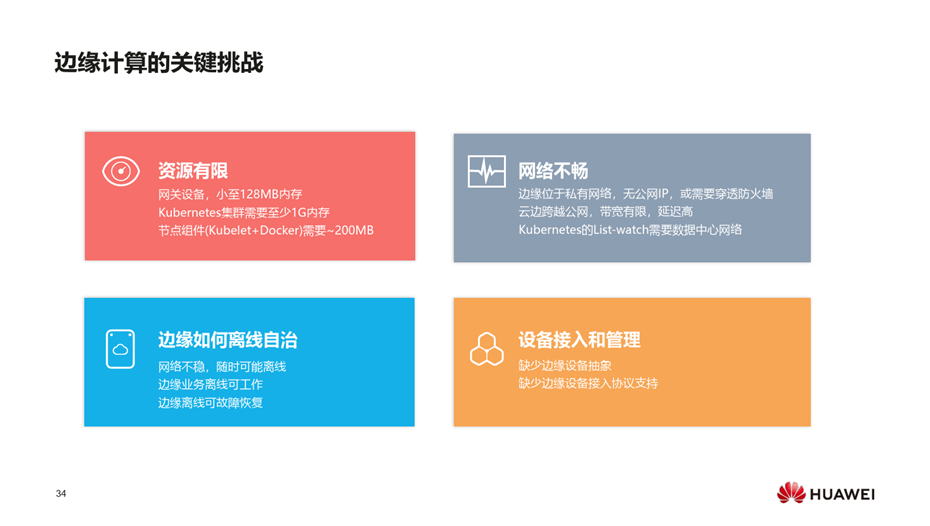
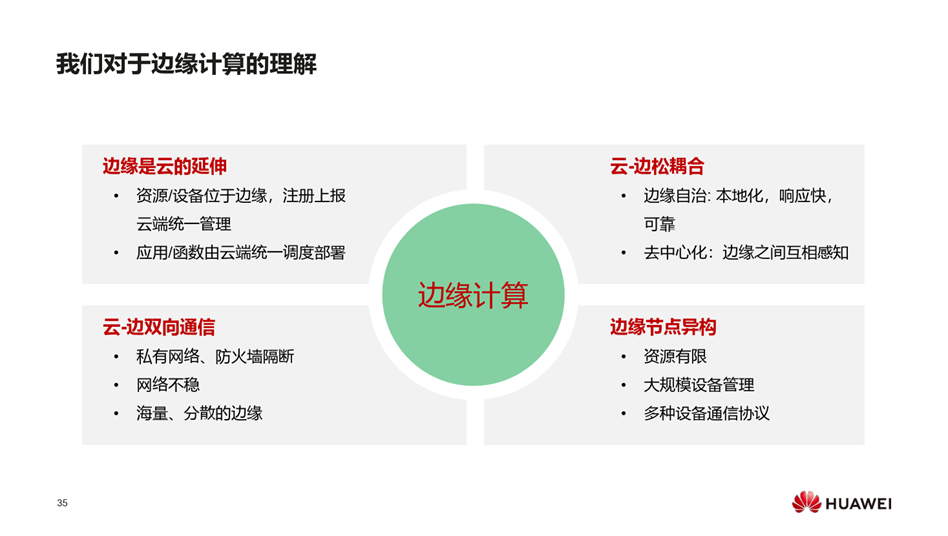




视频地址:
https://hdcwebinars.huaweicloud.com/watch/ko4g9lyo
如需本文的PDF版本,请联系助手获取 。






评论前必须登录!
立即登录 注册